The dissertation programme for MSc Urban Spatial Science, as of 2025/2026 AY, has an opportunity for candidates to take up partner/staff
projects on top of proposing an original research idea (although everyone was also required to think of one original idea in case that they
were unable to get allocated to any partner/staff projects).
I have successfully applied for a partner project, and it is with the
Centre for Cities (CfC), an urban-focused think tank based in London that looks at
urban issues related to British cities (sounds a lot like the British version of UofT School of Cities, eh? 🤣). My CASA supervisors are
Esra Suel and Clara Peiret-Garcia, while my CfC supervisor is Rob Johnson.

Esra Suel

Clara Peiret-Garcia

Rob Johnson
Essentially, this dissertation aims to be an extension of a recently-published work by the CfC that looks at how several large British cities outside of London may stand to benefit ECONOMICALLY if they could improve their local public transport provision. The metric is based on how many of the cities' working population could have a 'reasonable' journey to their respective city centres based on the actual time taken by public transport. The focus on city centres is because they were building on one of their previous works (that I will have to do a Lit Review on it, fairly soon!) which found that in the post-COVID environment, the most productive sector -- the knowledge services sector -- is strongly concentrated in city centres. If more people could get to these places, it meant that more people could directly or indirectly partake in, and benefit from, this highly productive sector. This in turn benefits the cities economically. The baseline conditions for a 'reasonable' journey are as follows:
- only one bus/train/tram ride, no interchanging
- on services provided for local commuting, not on National Express-style or tourist sightseeing services
- one should not wait for more than 15 minutes for a bus OR 20 minutes for a train/tram
- one should not walk for more than ten minutes to the bus stop OR 16 minutes to the train station/tram stop
- the PUBLIC TRANSPORT LEG of the journey should not take more than 30 (or 45) minutes to the city centre (so overall commute time if you include walking is actually 61 minutes at maximum)
- the end time of the journey is between 0845 and 0915 hrs on a specific midweek day in September 2025
They compared how this metric, based on the baseline conditions, would change if the public transport provision could be improved these three ways
- Modal Integration: What if you allow for JUST ONE interchange (hop on a bus followed by a train/tram)?
- Increased Bus Frequencies: What if you amend Criteria 3 to include for bus services where one has to wait for up to 30 minutes? The idea is to consider what happens if you increase the frequency of buses that currently turn up twice or thrice per hour into four times per hour?
- Reduced Bus Journey Times: What if, by any reason, the actual BUS journey times could be reduced by 15%? Basically amending Criteria 5 such that actual 35-min bus journeys => 30-min and actual 53-min bus journeys => 45-min. No changes to train/tram journey times.
The outcome of this research has also been visualised by CfC, click on the image below!
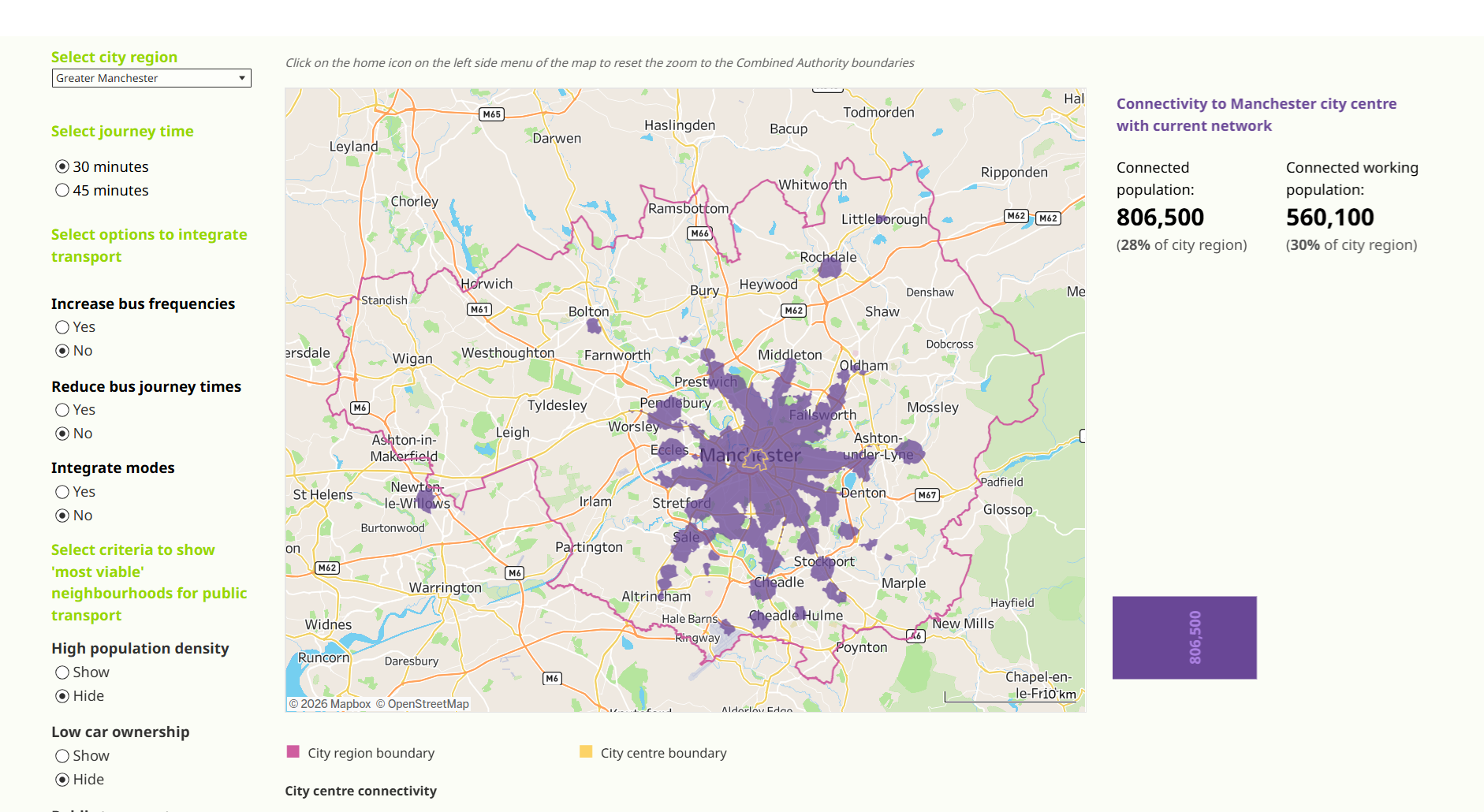
Where I Seek to Contribute to This Research
Based on this initial context, there are four lines of inquiry that I am interested to explore:- How many people ACTUALLY benefited from a direct 30/45 min journey to work at the city centre based on actual bus travel times?
- How many people SHOULD HAVE benefited from a direct 30/45 min journey to work at the city centre based on scheduled bus times but don't because actual bus times are slower?
- How many people OUGHT to have a direct 30/45 min journey to work at the city centre but can't because scheduled bus times just cannot even afford them the opportunity to begin with?
- Using spatial interaction modelling, how will these three numbers change when the three improvements take place?
Why? The CfC research uses actual bus travel journeys to generate their findings. This already puts it apart from current
literature because most research uses scheduled bus travel journeys instead. Actual bus travel journeys always take longer than scheduled, but by how
much? This is already an expansion that has been identified by CfC and CASA for the candidate (ergo, me) to look into for the dissertation project,
thus informing the first and second inquiry lines.
It is also standard across most literature that I have seen to report public transport accessibility based on how much of the population lives within
a certain amount of travel time to a point. However, just because you happen to live in a location that is 30 or 45 minutes away from the city centre does
not necessarily mean that you will work at the city centre. Similarly, just because you live more than 45 minutes away from the city centre does not
necessarily mean that you don't work at the city centre. I thought that accessibility analysis should also be coupled with data about actual travel
demand!
Additionally, I am starting this work fresh after completing the final coursework for
CASA0002: Urban Simulation, where I was
introduced to Origin-Destination (OD) matrix and Spatial Interaction Models. Basically, the former conveys information about where people start
and end their journeys in a matrix (essentially a data about flows of people across space), and the latter is a tool that uses data from the former to
predict changes in these flows based on changes at the origin, destination, or with the journeys between the two places.
Putting them together, what if we amend the metric for the baseline condition based on the OD matrix instead of getting the total number of working
adults who may live within the isochrones? Doing so will provide us with a picture of
how many people who ACTUALLY takes that 'reasonable' journey to the city centre (Inquiry 1) and how many people SHOULD HAVE BEEN able to take
that 'reasonable' journey (Inquiries 2 and 3). Furthermore, we can use Spatial Interaction Modelling to predict
what could ACTUALLY happen to the flows towards city centre - or maybe across the city region - if the three aforementioned improvements take
place (Inquiry 4).
As of today, I have yet to formulate a central research question to connect these four inquiries...
I took a fairly long break from my dissertation because I went to Switzerland for
Ice Hockey World Championships and was rudely welcomed by
a week-long heatwave upon my return to London. But before I left, I
was able to have my first in-person meeting with Rob at the CfC office on Monday (May 18) and consultations with Esra and Clara on Tuesday (May 19).
That meant that the dissertation was still somehow lingering at the back of my mind as I cheered for Team Canada and suffered through the heatwave
🫠.
Takeaways from Rob's Meeting on May 18
Firstly, I misunderstood condition 5 of the baseline conditions from the CfC report. As you can scroll from above, I thought that ONLY the public transport leg of the journey has the limit of 30 or 45 minutes. However, I have been clarified that it was the ENTIRE journey that has to be within 30 or 45 minutes flat, not a potentially 61 minutes commute. The workflow for CfC's research, I have come to understand, may have actually went like this...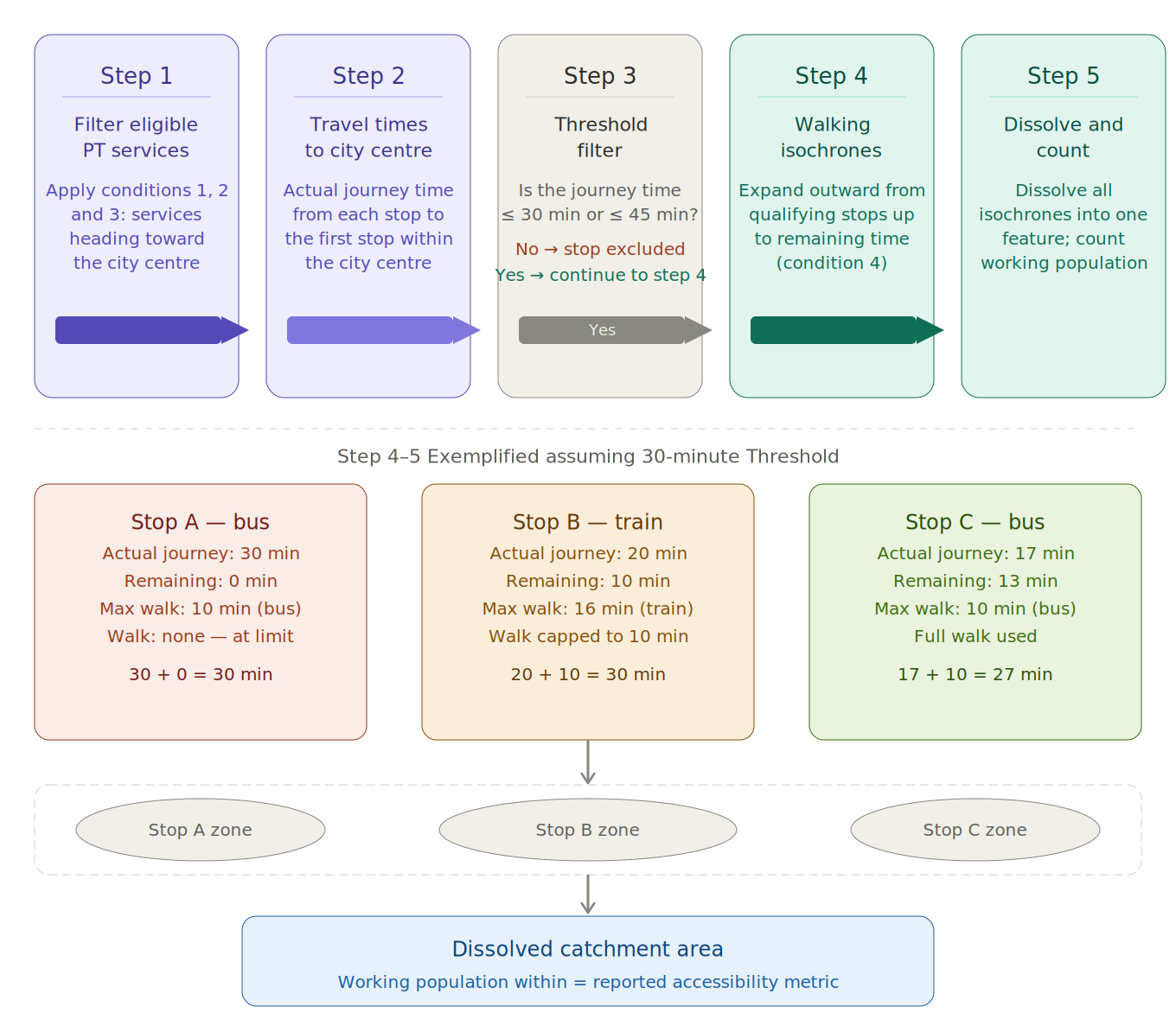 I asked Claude to create this flowchart of how I understood CfC's methodology after clarification
I asked Claude to create this flowchart of how I understood CfC's methodology after clarification
Secondly, Rob and I discussed about the OD Matrix Woes (see my ramblings on this). One
of the solutions he proposed as of now is to actually use one of the counterfactuals produced by ONS assuming pre-COVID commuting patterns considering
that the Locomizer data was still during COVID and I have yet to get access to the Huq data. I offered to do a sanity check of that dataset with
the post-COVID travel diary survey from Greater Manchester and likely from Greater London too, to
see if at least the data matches/falls in the same ballpark at the regional level. I am exploring to use Pearson's correlation to do this comparison
and I will update more in the OD Matrix page! However, that means that the validity is only checked at specific regions, and if I were to expand to
other cities like Bristol or Nottingham, we would be assuming that the counterfactual data is representative of those regions too without any checks.
Thirdly, Rob shared the private Github repo that CfC relied on to create their report. This crucially has the data on the city centre boundaries, which
will supplement the quick-and-dirty accessibility analysis that I have already produced. I
also found that CfC did their analysis in R, and I will have to make a decision on whether I want to continue my dissertation work in Python or convert
to R (or maybe do both!)
Takeaways from Esra and Clara's Meeting on May 19
The day was split into two parts, where in the first half Clara organised a workshop on how to do literature review and formulate the central research question (which I still have not concretised). I was introduced to Research Rabbit, a tool that lets users to list down the current papers that they have. The tool will then generate a network of papers arranged based on publication year and citation count (a measure of the paper's influence). The tool can then suggest papers that could connect between the foundational papers on concepts like transport justice with parallel research that looks at the transport justice in certain localities. I thought this is cool and I will be using it and sharing the map here as I embark on the literature review process (which I have not started and I know I need to do it soon, it is already June...)The second half was the meeting with Esra and Clara, where I shared the takeaways from Monday's meeting with Rob and my four lines of inquiry but the lack of an overarching research question. I was assured that this is a slightly better position than having a central research question but no detailed research plan because I can develop it as the research plan progresses, based on what good data is/becomes available. Due to the uncertainties with the OD data (which affects the feasibility of doing Spatial Interaction Modelling to project demand changes based on hypothetical improvements to the public transport system), Esra suggested a back-up option of exploring transport injustice between scheduled vs actual accessibility to the city centre in baseline conditions and in each of the three hypothetical improvements to the public transport network. The metric for comparison would revert back to the estimated population within the isochrones, in line with CfC and the rest of the literature, instead of using travel demand based on OD data.
As of now, my half-baked overarching research question is as follows:
To what extent does public transport in Manchester, Nottingham and Bristol perpetuate transport injustice by failing to provide workers with reasonable journey times to city centres due to unreliability and/or inadequate scheduling, and how would the commuting landscape change as a result of targeted service improvements?
It is exactly two weeks since I last updated this diary. Officially I am at an impasse. To be honest, after updating the boundaries, I had made a lot of
progress but it was a lot of one-step-forward-two-step-backwards kinda situation.
At first I thought that once I had the boundaries settled and the pipelines to build retrospective GTFS for buses ready, all I needed
was to pull in the scheduled GTFS for rail. This is the first roadblock - there's no archive of historical scheduled GTFS for rail anywhere. When I
pulled the rail timetable from Network Rail, that schedule is valid up until May 17, 2026. That's seven months after September 17,
2025 - the date that I have been using to do the quick-and-dirty analysis. So I need to
find another suitable date that falls AFTER May 17 to rebuild the retrospective bus GTFS data in order the to be in sync with the rail GTFS timetable.
Choosing an alternative date is a small issue in my larger scheme of things, so I initially chose June 3 and moved on to the r5py analysis stage to
model travel times based on scheduled and actual service patterns on all three cities of Manchester, Nottingham and Bristol. I had another small
dilemma here because my original method of choosing bus stop-to-bus stop to generate the travel times from each MSOA to city centre turned out to be
extremely time consuming. Using the population centroid at MSOA level was ruled out because a sidetrack experimental run I did in May resulted in
an MSOA in Manchester with no travel time modelled because the centroid happened to be so far off the road network that r5py could not model it. I did
not know why but the solution was quite simple - use population centroid at LSOA level, then generate travel times, then just get the median for the
entire MSOA. Even if one of the LSOA population centroids are not snapped to the road network, the other centroids could provide the values for the MSOA.
Eventually, it is not bus stop-to-bus stop travel times but LSOA centroids-to-bus stop travel times, and it has improved the processing times on Python
by sixfold!
The r5py analysis stage is important because it is the base for the cost matrix for my SIM to predict what happens to commuting patterns to city centre
after different types of service improvements. This is where the third issue came in - what kind of SIM do I use. Initially I thought that since I have
fairly absolute numbers about how many people live in the MSOAs, and how many jobs in the city centre, and since what is being changed is the travel
process and the cost matrices -- the right SIM should have been a doubly-constrained one. However, this is useful if only I have data breakdown of how
many people travel on public transport to work vis-a-vis other transport modes. By virtue of me
choosing the Locomizer Nov 2021 Mobile Phone Dataset, I do not have that. So, the
thing that I can observe by 'changes in commuting patterns' through SIM won't be 'how many more people take public transport to work at the city centre
due to the improvements', but rather 'how many more people could be attracted to work in the city centre due to the improvements'. This has changed my
dissertation to a question about job demand/labour force supply and how the poor bus service provision in the three cities may suppress this. That meant
that my suitable SIM should be an origin/production-constrained model, where the total number of outflows from each MSOA remains the same as in the
'baseline' OD data, but the sum of inflows could change. That change is the amount of suppressed demand that could be unlocked due to the improvements.
Now this is where I run into the fourth dilemma. Those of you who would have dealt with SIM before would know that it requires multiple destination. If
you have a production-constrained SIM but only one destination, what exactly would change to the flows even if the cost matrix/destination weights are
amended? That is where I consulted Claude while activating the 'Research' function, which gave me a fairly complicated answer that I still do not
understand till now. What I got was that I am no longer doing a conventional production-constrained SIM, I am doing an accessibility metric of each MSOA
to the city centre because limiting it to one destinations massively simplifies the gravity formula. It suggested that after I calculated this metric, I
should do a proper production-constrained SIM with two to three alternative employment centres in each city for sanity checking. If I'm going to
do a full proper SIM with several alternative destinations anyway, I might as well incorporate it into the original workflow and measure how the
suppressed labour force supply to the city centre could be unlocked in light of the competing destinations in the different improvement scenarios. But
then, how to select the alternative destinations? That put me right back to the drawing board with defining boundaries again. I tentatively
decided to use BRES data and select the top two MSOAs from each city that does not overlap with the city centre as the two alternative destinations and
run the production-constrained SIM accordingly.
That got me into my fifth dilemma, which is where I am right now. With the retrospective and scheduled GTFS datasets on buses (coupled with the
scheduled GTFS datasets on trams and rail), I can generate the actual median travel times, with the baseline criteria of only using one public
transport journey, and use it to calibrate the SIM. I can then swap out the cost matrix with median travel times based on scheduled datasets (what if
the buses actually run on time, how much of the suppressed supply could be unlocked), and based on allowing for multimodal journeys (what if I can
take the bus AND train because the ticketing is integrated, using the scheduled rail GTFS and retrospective bus GTFS together). But what about the other
two scenarios that CfC has explored in their paper?
- Reduced travel times based on a 15% reduction in bus journeys - this is ultimately similar to 'what if the buses run on time', but this is still conceptually separate and could provide valuable information on how to improve their bus provision in the most efficient manner. The thing is, I cannot just multiply the baseline cost matrix by 0.85 because the baseline cost matrix generated by r5py includes walking egress (journey from that population centroid to the nearest bus stop/s). If I just did a wholesale multiplication of the baseline cost matrix by 0.85, it would also shorten the time taken to do the walking, which does not happen and does not make sense.
- Increased bus frequencies, from those with at least two buses per hour to four buses per hour. I would need to massively edit the retrospective GTFS schedule and re-run r5py analysis to get the cost matrix to model this scenario in SIM. I cannot just edit the scheduled GTFS data because it would compound with the benefits of 'what if the buses run on time' scenario. Also, do I add in the frequencies for buses serving the entire city area or for buses only heading to/crossing through the city centre? Sometimes, some routes already have partial services active during the peak hours, so the same bus route has different frequencies depending on where you start the journey - so should this route's frequency be considered at its most frequent point or its least frequent point, and do we evenly add frequency throughout the entire service or do we just boost frequency at the infrequent parts of the route?
Basically, I am at the point where the large theoretical steps are in place. And the base codes are somewhat ready. But there are several methodological decisions that I need to make, especially with the fourth and fifth dilemmas, that needs to be supported by literature. I have, at this point, exhausted all the things I could possibly do WITHOUT doing a proper literature review. Now I need to face the demon that I have been delaying for so long, and I need to do the boring part of reading through everything...